Leetcode Meta面试高频题
Published:
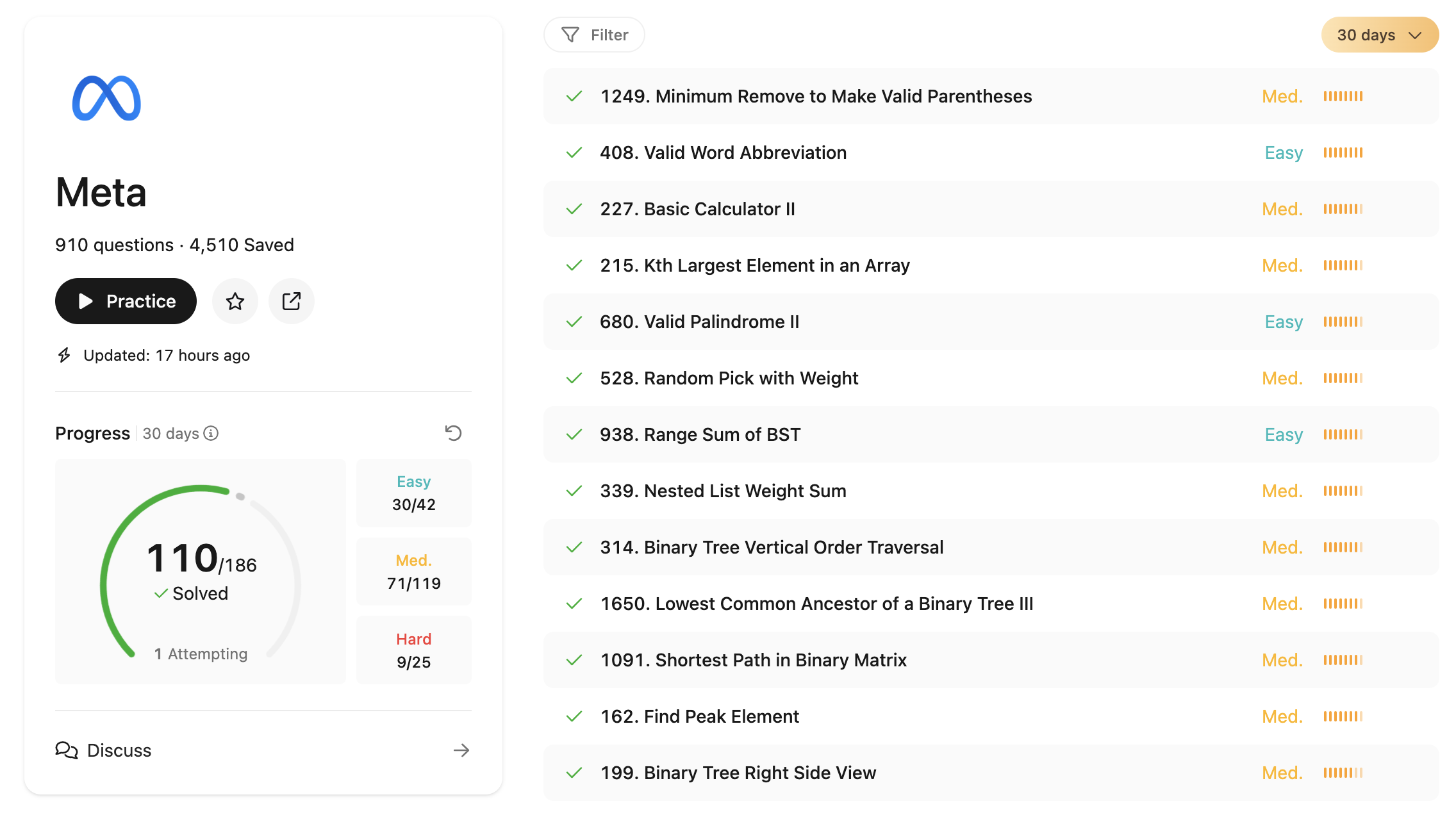
2024年9月份开始找全职的时候,接到了Meta的面试。面试包含很多coding环节,一般是要求在45min内解决两道coding问题。所以在这里总结Meta高频题(Top 100)的解题思路。
| 编号 | 题号 | 题目标题 | 题目链接 | 题目介绍 | 解题思路 | 详解 |
|---|---|---|---|---|---|---|
| 1 | 1249 | Minimum Remove to Make Valid Parentheses | Link | 字符串中有多余的括号,去除括号,使得括号的组合是合理的。 | 先把字符串转换为list,然后用栈来记录左括号的位置,遍历到右括号的时候,如果栈非空,则栈顶元素出栈,否则将对应的字符变为空字符。遍历完成之后,如果栈非空,则将栈内对应位置的字符设为空字符。 | |
| 2 | 408 | Valid Word Abbreviation | Link | 省略一部分字符,用字符个数代替,数字不能以0开头,同时两段省略字符串不能相连。 | 双指针。同步遍历原字符串和缩写字符串,如果是字母,比较是否相同,如果缩写字符串是数字,则将原字符串指针向后移动相应位置。当一个指针到达字符串末尾时,另一个指针也要到达末尾,否则就不是合规缩写。 | |
| 3 | 227 | Basic Calculator II | Link | 计算一个表示加减乘除运算的字符串的运算结果,字符串只包含加减乘除、数字和空格。 | 遍历字符串时,用pre_op储存上一个操作符。遇到数字,累加得到操作数字;遇到空格,跳过;遇到运算符,则查看pre_op,如果是加减号,则把当前操作数按正负存入栈中,若是乘除号,则栈顶元素出栈,和当前操作数运算后再入栈。最后返回栈中所有数字的和。 | |
| 4 | 680 | Valid Palindrome II | Link | 给定一个字符串,在允许至多删除一个字符的情况下,是否可以得到一个回文字符串(Palindrome)。 | 双指针,一个左至右,一个从右至左。向中间靠拢,判断所指字符是否相同。如果遇到字符不同的情况,则分别判断去除左指针字符和去除右指针字符后,是否是一个回文字符串。需要一个标志符,来显示是否已经去掉字符了。(递归) | |
| 5 | 215 | Kth Largest Element in an Array | Link | 找到数组中第k大的数。 | 快速选择,基于快速排序。选定pivot,把数组划分为比pivot小,和pivot相等,比pivot大的部分,通过三个数组的长度,来判断第k大数组位于那个子数组,再对其进行快速排序。运用heap,构造一个包含k个元素的heap,heap顶部元素为heap里面的最小值。 | |
| 6 | 314 | Binary Tree Vertical Order Traversal | Link | 一个二叉树,返回垂直检索序列。返回的是一个链表,链表每个元素是同一列的元素,并且按照从上到下排列。 | 前序遍历二叉树,给每个node分配(row, column)表示其位置,并且按照column位key放入一个dictionary中。然后按照key从小到大输出元素,每个元素均为处于同一column的数字链表。(递归) | |
| 7 | 339 | Nested List Weight Sum | Link | 一个新定义的类 NestedInteger,包含一些API。一个NestedInteger可能只包含一个整数,也可能是一个包含整数的链表。求每个整数与其在链表中深度的乘积和。 | 深度优先遍历链表,对于每个元素,若为只包含一个整数的NestedInteger,则加上weighted number,否则进入调用深度优先函数,进入下一层链表。(递归) | |
| 8 | 1650 | Lowest Common Ancestor of a Binary Tree III | Link | 一个二叉树,每个节点不仅包含值、指向左右子树的指针,还包含其指向其父母的指针。求两个节点的最小共同祖先。 | 假设两个节点分别为p和q,二叉树的根节点为root,p和q的最小共同祖先为target,那么路径p->root->q->target和q->root->p->target的长度是相同的。所以根据这个思路,可以从p和q向上溯源,知道访问到target节点。(注意循环中有可能已经访问到target节点了) | |
| 9 | 236 | Lowest Common Ancestor of a Binary Tree | Link | 求二叉树中两个节点p和q的最低共同祖先节点。 | 最小公共子节点拥有一个特性:其左右子树分别包含p和q。所以,首先判断当前节点是不是p或者q中的一个,如果是,则返回当前节点。否则,判断当前节点左右子树分别包含p和q,如果是,则当前节点即为p和q最低共同祖先。 | |
| 10 | 938 | Range Sum of BST | Link | 求二叉树中节点值位于给定范围内的和。 | 遍历树中每个节点(深度优先,广度优先,前/后/中序遍历),判断节点值是否位于给定范围,若是,则加到最终的结果中去。 | |
| 11 | 528 | Random Pick with Weight | Link | 给定一个权重数组,数组每个值代表当前位置的权重。部署一个随机选择位置的函数,每个位置被选中的几率正比于该位置的权重。 | 求权重数组的累积分布函数(Cumulative Distribution Function)。然后,在1和权重和之间随机生成一个数,生成的随机数在cdf中的所处位置就是应该返回的位置。在cdf中查找随机数的时候,要用二分法查找。 | |
| 12 | 71 | Simplify Path | Link | 简化表示unix路径的字符串。 | 用’/’将字符串分割为list,遍历这个list,如果元素是’.’或’‘,直接删除,如果是’..’,则删除当前元素和上一个元素(注意遍历下标的变化)。最后用’/’将list中的字符串连接起来,返回。 | |
| 13 | 1091 | Shortest Path in Binary Matrix | Link | 给定一个grid,由0和1组成,求从grid左上角到右下角最短路径。要求路径上的元素均为0。 | 运用队列,广度优先遍历grid中的0元素点,每一层路径节点数加1,直到访问到右下角节点,返回路径长度。 | |
| 14 | 199 | Binary Tree Right Side View | Link | 求一个二叉树从其右方看到的数从上到下组成的数组。 | 递归法:分别求左右子树的从右方看到的数组,然后比较其结果,生成最终结果(右子树结果会遮挡左子树结果)。或者广度优先遍历树,每一层最后一个元素即为该层从右方看到的结果。 | |
| 15 | 1570 | Dot Product of Two Sparse Vectors | Link | 存储稀疏矩阵,并且创造求稀疏矩阵内积的函数。 | 用directionary存储稀疏矩阵,key是位置,value是数值。求内积的时候,相同key的value乘积。注意遍历长度较小的directionary。 | |
| 16 | 88 | Merge Sorted Array | Link | 合并两个有序数组,结果存储到其中一个数组中。 | 从右向左依次比较两个数组的元素,大的那个被选中,存入合并后的数组中,并更新对应指针。注意其中一个数组可能向遍历完。 | |
| 17 | 50 | Pow(x, n) | Link | 利用普通运算符实现Pow(x, n)函数。 | 联想n的二进制形式,Pow(x, n)即是由x的一系列幂的乘积。如Pow(x, 10),10 = b1010,则Pow(x, 10) = x^8 * x ^2。所以可以对n进行位运算,每次向右移动一位,x更新为对应的幂,当n二进制末尾为1的时候,结果乘以x的值。直到n位0为止。 | |
| 18 | 162 | Find Peak Element | Link | 找到数组中的一个峰,峰定义为数组元素比前后元素都大。同时规定,数组边界外为无限小。 | 二分查找。左右指针,分别从左往右、从右往左,向中间查找。每次查找中间元素,若该元素比临近元素大,则返回该元素位置。否则则有两种情况:(1)该中间元素不大于其右边元素,则待查找元素必位于右半部分;(2)该中间元素大于其右边元素(即不大于其左边元素),则待查找元素必位于左半部分。注意循环条件:left < right - 1。这样可以使得mid元素始终有邻近元素,同时可以处理数组长度小于3的情况。最后返回时要返回left和right中对以应元素大的那个。 | |
| 19 | 543 | Diameter of Binary Tree | Link | 二叉树的直径为树中距离最远的连个节点之间的距离,注意这两个节点不一定要穿过根节点。。 | 定义一个计算每个节点深度的函数,该函数递归式地计算节点左右子树的深度,该节点深度则为左右子树深度较大值加1。在这个过程中,评估穿过每个节点的最长路径,即左右子树深度之和。遍历所有节点之后,即可得到最长路径的长度,即diameter。 | |
| 20 | 146 | LRU Cache | Link | 设计一个数据结构,遵循Least Recently Used (LRU) cache的规则。 | (1) 利用collections.OrderedDict模块,保持插入键值的顺序。访问某个键时,获得对应的值后将该键移除后重新插入,使得它位于字典头部。插入键值时,如果存储空间满了,则需先移除字典尾部元素,再插入新键值。(2)如果不允许使用该模块,则可以利用双向链表实现,保存链表首尾,方便插入、删除。同时维持一个字典,可以快速访问键值。 | |
| 21 | 1 | Two Sum | Link | 给定一个数组,找到两个元素,其和为固定值target。 | (1) 先把数组排序,然后利用双指针来寻找两个元素。(2)创建hashmap,键为元素值,值为元素位置。遍历数组,利用target和元素值来查询是否哈希表中已经有对应元素了。 | |
| 22 | 125 | Valid Palindrome | Link | 判断一个字符串中的英文字符组成的字符串是否是会问字符。 | 首位指针,对于非英文字符,跳过。英文字符则比较首位指针对应字符是否一致,不一致则不是回文字符串。注意一些字符串操作函数:lower,isalnum等。 | |
| 23 | 791 | Custom Sort String | Link | 给定一个字符串,和一个字符串order,按照order中字符顺序来排列字符串。 | (1)按照order中字符,设定26个英文字母的顺序,按照这个顺序利用sort函数来排列字符串。(2)创建一个hashmap,统计字符串中每个字符的频率。然后遍历order字符串,如果字符在hashmap中,则按照频率扩展字符串。最后,再把没有在order中出现的字符附加上去。 | |
| 24 | 921 | Minimum Add to Make Parentheses Valid | Link | 给定一个由左右括号组成的字符串,问最少添加多少额外的括号,使得该字符串是正确的括号组合。 | 两个变量left和right分别记录左右括号数量,遍历字符串,若为左括号,则left加1,若为右括号,若left大于0,则left减1,否则right加1。最后返回left+right。 | |
| 25 | 973 | K Closest Points to Origin | Link | 给定一系列二维点,返回k个离原点最近的点。 | k最小值问题。可以用栈来解决,也可用快速选择来解决。用栈,可以用heapq模块,注意栈是最小栈,而且heapq支持元素为tuple或list,根据元素第一个值来构建栈。 | |
| 26 | 1762 | Buildings With an Ocean View | Link | 一个数组代表一排从左至右楼房高度,求那些可以看到右边大海的房子。 | 从右至左遍历数组,记录当前最高楼的高度,若遇到更高的楼,则代表在该楼可以看到大海,并更新最高楼高度。 | |
| 27 | 56 | Merge Intervals | Link | 一个数组代表一排从左至右楼房高度,求那些可以看到右边大海的房子。 | 从右至左遍历数组,记录当前最高楼的高度,若遇到更高的楼,则代表在该楼可以看到大海,并更新最高楼高度。 | |
| 28 | 138 | Copy List with Random Pointer | Link | 给定一个链表,每个链表不仅包含值和指向next的指针,还有一个随机指针,指向链表中一个随机元素,或者指向空指针。复制该链表。 | (1)构建一个hashmap,key是原node,value是复制的node。遍历链表,连接起每个节点对应的复制节点。(2)对于每个节点,复制一个节点,并将复制的节点插入原节点和其next节点之间。这样,奇数位置节点为原节点,偶数位置节点为复制节点。然后再遍历该链表,根据原节点的random指针指向,连接复制节点的random节点。第三次遍历链表,把原节点和复制节点拆分成两个链表。 | |
| 29 | 560 | Subarray Sum Equals K | Link | 给定一个数组,求其子数组的个数,要求子数组和等于一个给定值k。 | 所谓子数组的和,其实就是数组cdf两项之差。所以构建一个以数组累和为key的hashmap,key对应的值为该类和出现的频次。遍历数组,更新累和,寻找子数组等于给定值的个数。 | |
| 30 | 426 | Convert Binary Search Tree to Sorted Doubly Linked List | Link | 将一个二叉树转化为双向链表,且链表首尾要相互连接。 | 递归。对于一个节点,如果该节点无左右子树,则该节点组成的双向链表首尾均为该节点。定义一个函数,可以把二叉树转化为双向链表,同时返回该链表首尾节点。分别转化一个节点的左右子树,根据左右子树生成双向链表首尾来插入双亲节点。 | |
| 31 | 31 | Next Permutation | Link | 看链接。 | (1).从数组最右端向左遍历,找到第一个不满足nums[i] >= nums[i + 1]的位置,然后使得pivot = i;(2).若pivot = -1,说明该数组是最大的permutation,将该数组翻转即可;(3).若pivot >= 0,则再次从最右端向左遍历数组,找到第一个逼nums[pivot]大的数的位置,为right_swap;(4).交换nums[pivot]和nums[right_swap]的值;(5).将数组中pivot右边元素翻转,即nums[pivot+1:].reverse()。 | |
| 32 | 1004 | Max Consecutive Ones III | Link | 给定一个只包含0和1的数组,可以将其中最多k个0变为1。在这种情况下,可以得到最长的连续为1的子数组长度。 | 滑动窗口。左右指针确定一个窗口,先固定左指针,向右移动右指针,同时统计窗口内0的个数,当0的个数不大于k时,可一直向右移动右指针。当窗口内0的个数大于k或者右指针超过数组长度时,可以统计窗口长度。移动左指针,重复这个操作,可以得到一些列的最长窗口长度。在这个过程中,记录最长窗口长度。 | |
| 33 | 346 | Moving Average from Data Stream | Link | 部署一个数据结构,可以保存一序列数字。该序列有最大长度,超过最大长度时,需要去除头部元素后再插入尾部元素。插入元素时,需要返回插入后,序列的平均值。 | 保存当前序列的和以及长度(元素个数)可以方便计算序列平均值。 | |
| 34 | 129 | Sum Root to Leaf Numbers | Link | 一个二叉树,规定从根节点到叶子节点的数字串组成一个整数,求所有可能整数的和。 | 深度优先遍历树,同时将当前节点对应数字加到组成整数后面(num = num * 10 + val),当遍历到叶子节点时,把该整数值加到最终结果里面。 | |
| 35 | 347 | Top K Frequent Elements | Link | 给定一个数组和整数k,返回出现频率最高的k个数。 | 用一个hashmap来存储数字以及其出现的频次。根据这个hashmap来生成一个list,每个元素是一个二元tuple,第一个值为频次,第二个值为数字本身。用heapq构建栈,就可以得到出现频次最大的k个数字。 | |
| 36 | 23 | Merge k Sorted Lists | Link | 把k个排好序的链表合并,合并后的链表也要是有序的。 | 部署一个函数用来合并两个链表。在合并链表时采取归并法,减少调用合并函数的次数。如果将链表中的n个链表从左至右依次合并,需要调用n-1次合并函数。但是如果采取归并的方法,则大概只需调用log(n)次合并函数。 | |
| 37 | 670 | Maximum Swap | Link | 对于一个正整数,你最多可以调换其中两位数字的位置。这样操作可以得到的最大整数是多少。 | 从左至右遍历每一位数,直到数字不是降序,设第i位数字是降序序列的最后一个数。则可把该整数划分为两部分:前半部分由前i+1个数字组成,后半部分数字组成第二部分。则在后半部分找到最大且位于靠后位置的数字,将其与前半部分比它小的最高位数字交换,即可得到结果。 | |
| 38 | 986 | Interval List Intersections | Link | 两个list,分别包含一系列的间隔,每个间隔由起点和终点组成。求这些间隔的重叠部分。 | 双指针,分别指向两个队列中的间隔。如果当前指针指向的两个间隔有重叠则把重叠部分放到结果中。双指针的更新只和指针指向的两个间隔的终点有关。 | |
| 39 | 863 | All Nodes Distance K in Binary Tree | Link | 给定一个二叉树和其中一个节点,求所有距离该节点k长度的节点的值的集合。 | 递归。首先需要知道所有节点的双亲节点,所以可以用一个hashmap,从根节点递归遍历每个节点,然后把每个节点与其对应的双亲节点存入hashmap中。然后从目标节点target开始,广度优先遍历二叉树,每向外走一步,距离就增大一步。遍历二叉树时,如果距离等于k则把改值存入结果中。在遍历时,需要一个visited集合,来存储已经访问过的节点。 | |
| 40 | 1539 | Kth Missing Positive Number | Link | 给定一个严格递增正整数数组,和数组[1, 2, 3, …]相比缺失一些数字,求缺失的第k个数字。 | 每个数字减去其位置(1开始)就是当前缺少的数字数。对此可以用二分查找法,找到缺失数字所在区间。 | |
| 41 | 133 | Clone Graph | Link | 复制一个图,图由节点组成,每个节点包含一个指向其邻近节点的list。 | 深度优先遍历图,每访问一个节点,对其进行复制,同时存入一个 hashmap中。hashmap的key是原节点,value是复制的节点。在遍历时即可把每个节点的邻近节点同时复制。要用一个set记录已经访问过的节点。 | |
| 42 | 766 | Toeplitz Matrix | Link | 判断矩阵的条对角线上的元素是否相等。 | 遍历除第一行和第一列的每个元素,如果出现a[i][j] != a[i - 1][j - 1],则返回false,否则返回true。 | |
| 43 | 163 | Missing Ranges | Link | 在给定的范围内,寻找数组中缺失的数字间隔。 | 比较相邻数字,若相邻数字差1,则继续遍历,否则插入缺失的数字间隔。 | |
| 44 | 1047 | Remove All Adjacent Duplicates In String | Link | 给定字符串若存在连续相同字符,则移除它们,移除后的字符串如果出现新的连续相同字符,也要移除。最后的结果不能包含连续相同字符。 | 用栈来处理。遍历字符串时,不断比较当前字符和栈顶字符,若相同,则出栈,否则进栈。 | |
| 45 | 958 | Check Completeness of a Binary Tree | Link | 给定一个二叉树,判断它是否是一个完全二叉树。 | 层序遍历二叉树,判断空节点之后是否有非空节点。是,则不是完全二叉树,否,则是完全二叉树。 | |
| 46 | 827 | Making A Large Island | Link | 给定一个矩阵,由0和1组成,0代表大海,1代表陆地。连通(4-连通)的1组成一个个岛屿,在最多将一个0变为1的情况下,求能得到的最大岛屿面积。 | 遍历每个0,判断其周围是否有1。若是,则说明该0有可能连接周围的岛屿。对于周围存在1的0,对每个1寻找其所在的岛屿面积。在这个过程中,需要记录已经访问过的位置。最后看一看0的周围有几个岛屿可以被连接起来,所能得到的最大面积是多少。为了提高效率,要记录访问过的岛屿(一个dictionary,key是位置,value是所在岛屿的面积)。solution | |
| 47 | 380 | Insert Delete GetRandom O(1) | Link | 实现一个数据结构,主体是一个set。支持值的插入,删除,以及返回set中一个随机位置的值。 | python set数据结构的使用。set.remove(a), set.add(a), random.choice(list(set))。 | |
| 48 | 76 | Minimum Window Substring | Link | 给定两个字符串s和t,求s的子串,使得t中所有字符(包含重复的)都包含在该子串中。求最短的字串。若没有,则返回空字符串。 | 滑动窗口。用一个Counter变量t_counter统计t中字符频数。用i,j来作为滑动窗口起止位置。在s[i-j]内的字符频数也用一个Counter变量统计。用一个变量matches来记录已经匹配的字符数目。当所有字符已经匹配时,记录当前长度,若比以前的结果小,更新结果。右移i,减小窗口长度,同时更新s_counter和matches。当未完全匹配时,右移j,更新s_counter和matches。 | |
| 49 | 65 | Valid Number | Link | 判断一个给定字符串是不是一个有效的数字表示,字符串中包含[’+’, ‘-‘, ‘e’, ‘E’, ‘.’, ‘0-9’] | 用四个布尔变量num,sign,exp,dec来分别代表数字,正负号,指数符号,小数点是否出现。遍历字符串,通过当前字符和四个布尔值的情况判断该字符串是否可以组成有效数字。例如,正负号出现以后,在没有遇到小数点或者指数符号之前,正负号不可以再次出现。遇到指数符号时,需要重置四个布尔变量。 | |
| 50 | 2 | Add Two Numbers | Link | 两个链表,链表元素表示两个非负整数的数字,求这两个数的和,也用链表表示返回。 | 用变量carry表示进位。两个指针分别指向两个链表头指针。当两个指针有一个非空,或carry不为0时,执行循环。遍历链表每个数字,求和,根据和在结果链表中添加新节点并更新carry。用一个dummy指针会比较省事。循环结束后,需要判断carry是否为0,不为0则需要再添加一个节点。 | |
| 51 | 282 | Expression Add Operators | Link | 数字组成的字符串,在数字间添加’+’,’-‘,’*‘,使得所形成的表达式的运算结果等于target。 | 假定num是字符串,例如’123456’。深度优先搜索,定义dfs函数:dfs(i, path, cur_num, prevNum),其中path是num[:i]组成的表达式字符串,cur_num是path的运算结果,prevNum则是path中最后一个加入的值,可以是正数,负数,或者几个数的乘积。以此为基础,如何递归调用dfs函数得到最终的表达式? | |
| 52 | 116 | Populating Next Right Pointers in Each Node | Link | 完美二叉树同一层的节点从左到右连城链表。 | (1)层序遍历二叉树,用一个queue存储每一层节点,然后从左到右出queue,连接起来。(2)层序遍历二叉树,用queue存储每一层节点,连接queue队首节点的左右子节点,同时连接相邻节点的右左子树,用next连接。 | |
| 53 | 173 | Binary Search Tree Iterator | Link | 给定一个二叉搜索树,如何有效地访问中序遍历的每个节点。 | 直观方法是创建数据结构时,直接把中序遍历节点按次序保存在一个list里面。但是,这样会很耗费空间。有效方法是用一个栈保存从根节点到最左边节点的所有左子树节点。则栈顶就是中序遍历第一个节点。每次指针向后移动一位,则栈顶节点出栈,同时把其右子树的左子节点依次入栈。solution | |
| 54 | 270 | Closest Binary Search Tree Value | Link | 给定一个二叉搜索树和一个浮点数target。求二叉搜索树中距离target最近的值,如果不止一个,则返回较小的那个。 | 递归法。判断根节点和target的大小,然后决定继续在左子树还是右子树继续寻找最近值。寻找到以后,再和根节点比较,看哪一个更近。 | |
| 55 | 415 | Add Strings | Link | 两个由数字组成的字符串分别代表两个正整数,求它们代表正整数的和,结果也要由字符串表示。不可使用直接把字符串转化为数字的内置函数。 | 从两个字符串的低位到高位,依次相加,同时考虑进位carry,最后的结果也用字符串表示。 | |
| 56 | 1216 | Valid Palindrome III | Link | 一个字符串最多移除k个字符,这样操作可以得到回文字符串吗? | 要利用collections.lru_cache来提高效能。定义一个validPalindrome函数:validPalindrome(s, l, r, numOfChoices),其中s代表给定字符串,该函数判定l与r之间的子字符串是否是回文字符串,numOfChoices则代表已经去掉了多少字符。显然当字符串不够成回文字符时,因为有两个字符不匹配,因此可以去掉其中一个字符,再继续比较剩余字符串。 | |
| 57 | 1644 | Lowest Common Ancestor of a Binary Tree II | Link | 求二叉树两个节点的共同祖先。这两个节点有可能不在二叉树中,这时,返回空。 | 递归。判断节点是否是空,等于其中一个节点。若等于其中一个节点,则需要对其左右子树继续查询,看看另一个节点是不是其子节点。对于一个节点,若两个节点分别位于其左右子树中,则该节点即为最小共同祖先。用两个布尔值来记录是否找到两个节点。 | |
| 58 | 169 | Majority Element | Link | 数组中有一个数字出现次数超过数组长度一半,找出该数字。 | 排序后,中间位置的数字即为所求数字。 | |
| 59 | 200 | Number of Islands | Link | 一个二维字符数组。数组中’1’代表陆地,’0’代表海洋。求在四连通的情况下,有多少个岛屿。 | 遍历数组,对于每个’1’,由其开始深度优先遍历grid,找到所有连接的’1’。访问过的’1’,变为’0’。若要求不能改变数组,则需要一个visited二维数组。 | |
| 60 | 219 | Contains Duplicate II | Link | 一个数组,判断是否存在两个相同的数,它们位置之差不大于k。 | 遍历数组时,用一个dictionary记录某个数字最近出现的位置。遍历到某个数字时,判断该数字是否在字典中,若在,判断当前位置和该数上次出现位置之差是否不大于k,若是,则返回True。每次都要更新字典。 | |
| 61 | 249 | Group Shifted Strings | Link | 字符串中的字符允许整体平移(abcdef..z),在这种情况下把可以通过平移得到的字符串聚在一起。 | 可以通过平移得到的字符串有一个共性:相邻字符间的距离是固定的。所以可以用这个距离来编码,把编码相同的字符串聚集在一起。 | |
| 62 | 253 | Meeting Rooms II | Link | 给定一系列会议的起始时间,求最少需要分配多少个会议室。 | 核心在于用一个最小堆来存储已分配会议室的最早可用时间,即在该会议室举行会议的最晚时间。首先要把intervals数组排序,按照开始时间排序。 | |
| 63 | 498 | Diagonal Traverse | Link | 给定一个mxn的二维矩阵,求沿着45度对角方向遍历矩阵所得到的数列。 | 在45度对角线上的元素,横纵坐标是固定的,所以可以以它作为key来建立一个字典把在同一对角线上的元素聚合起来。在把这些元素合起来时,根据key的奇偶性来判定是否需要反转数列。 | |
| 64 | 647 | Palindromic Substrings | Link | 给定一个字符串,求该字符串有所少个回文子串。 | 回文字符串的查找需要从其中间向两边扩展寻找。所以遍历字符串每个位置i,分别以left = right = i和left = i, right = i + 1来扩展寻找回文子串。每当得到一个回文子串,count加1。 | |
| 65 | 987 | Vertical Order Traversal of a Binary Tree | Link | 给定一个二叉树,给每个节点确定一个行数和列数(row, column)。规定从根节点开始,每个节点的左子节点行数加1,列数减1,右子节点,行数加1,列数加1。把该二叉树中的元素按照列数从小到大的顺序输出,同时同一列的元素聚在一起,按照行数排列。 | 先序遍历二叉树,用一个字典记录每个元素的值。其中,key是列数,value是节点值和行数。则遍历之后得到的字典就把在同一列的元素放在一起了。对于同一列的元素,则可以按照行数来排序输出。 | |
| 66 | 8 | String to Integer (atoi) | Link | 把字符串转化为数字,该字符串中包含一些无效字符,如空格,字母等。而且数字有可能超过32位整数,在这种情况下需要返回最大32位整数或最小32位整数。 | 用布尔值来控制是否继续读取字符。遇到数字时更新最终结果,可以直接与最大整数和最小整数比较:maxint = 2*31 - 1,minint = -2*31 - 1。 | |
| 67 | 9 | Palindrome Number | Link | 判断一个整数是否是回文数字(即从左到右和从右到左顺序排序的数字相等)。 | 计算数字从右到中间位的倒序数字,看看和原数字从左至中间位数组成的数字是否相等。 | |
| 68 | 14 | Longest Common Prefix | Link | 给定一些字符串,找到它们最长公共前缀。 | 可以先将字符串数组排序,然后逐个比较相邻字符串,找到最长公共前缀。 | |
| 69 | 20 | Valid Parentheses | Link | 由三种括号(’(){}[]’)组成的字符串,判定该字符串中的括号组合是否正确。 | 用栈判定所有括号是否成对。 | |
| 70 | 269 | Alien Dictionary | Link | 定义一个外星字母表,它们使用英文字母,但是字母顺序是未知的(即不再是’abc..xyz’)。现给定一些单词,已知单词顺序是按照字母顺序排列的,求外星语言的字母顺序。 | 拓扑排序问题,每个字母视为一个节点,用set数据结构存储每个节点的入节点和出节点,构造图。然后依次将入度为0的字母从图中去除,放到字母顺序表中。要注意:(1)孤立节点统一视为入度为0;(2)遍历单词时,如果a在b之前,b是a的前缀,说明这个排序是无效的;(3)若图中有环,则图无效(即图中仍有节点,却已经没有入度为0的节点了)。 | |
| 71 | 283 | Move Zeroes | Link | 把数组中所有的0移到数组后部,非0元素的相对顺序要保持不变。 | 从右向左遍历数组,若当前元素为0,则将该元素移除,同时在数组末尾附加0。 | |
| 72 | 494 | Target Sum | Link | 给定一个非负整数数组,你可以在整数之间添加‘+’和‘-’来组成一个表达式。求所有可能的表达式,使得其结果等于target。返回这种表达式的数量。 | 递归方法。单纯递归法时间复杂度太高,需要用一个dictionary来保存中间的运算结构。 | |
| 73 | 735 | Asteroid Collision | Link | 给定一个整数数组,数组中元素绝对值代表一个陨石的质量,正负代表方向:正数为向右,负数为向左。两颗相邻陨石,如果方向相反且相向运动,会发生碰撞。碰撞时,若二者质量相同,会一起爆炸,否则轻的陨石爆炸,重陨石方向和质量不变。求最终陨石的稳定状态。 | 用栈来遍历数组,比较当前陨石和栈顶元素的大小和符号,来决定是否入栈或者出栈。 | |
| 74 | 721 | Accounts Merge | Link | 给定一个list,list每个元素是字符串list。该字符串list的首个元素是用户名,其余元素是注册邮箱。注册邮箱重叠的用户可认为是相同用户,且相同用户的用户名相同。但是,用户名相同不保证是同一用户。把所有相同用户融合起来,去掉重复出现的邮箱。返回list中,每个list元素代表一个用户,用户之间不需排序,一个用户的邮箱要按照字符串排序结果排序。 | 用字典建立邮箱和用户index之间关系,即key是邮箱,value是使用该邮箱用户的index的集合。运用寻找连通域方法,找到同一个用户的所有index,并且融合它们。运用排序算法去除同一个用户的重复邮箱,并且对邮箱进行排序。 | |
| 75 | 636 | Exclusive Time of Functions | Link | 对于一个单线程cpu,单独时刻只能运行一个函数。函数的开始和结束使用字符串保存的,例如‘0:start:0’表示函数0在0时刻开始,‘0:end:6’表示函数0在6时刻结束。给定所有的字符串,求每个函数的运行总时长。 | 函数调用是用栈来安排的,所以用一个栈来模拟函数调用开始、结束的情况。栈的每个元素表示函数id和已经运行时长。同时用一个字典来记录每个函数运行总时长。每次有函数开始和结束,都要记录其时刻,方便计算函数运行时长。通过对字符串的遍历,依旧函数的出栈、进栈、更新函数运行时长,即可得到所求结果。 | |
| 76 | 529 | Minesweeper | Link | 扫雷游戏,根据规则去更新二维数组,直到扫到雷。 | 图的深度优先遍历。 | |
| 77 | 825 | Friends Of Appropriate Ages | Link | 给定一个正整数数组,每个元素代表一个人的年龄。每个人可以向别人发送好友请求,是否发送取决于二者的年龄,某人只会向满足一定年龄关系的人发送好友请求。求所有的好友请求数量。 | 统计每个年龄的频数,然后运用排列组合的方法计算朋友请求数目。在判定可以发送朋友请求之后,需要分两种情况:向同龄人发送,向不同龄的人发送。 | |
| 78 | 997 | Squares of a Sorted Array | Link | 给定一个整数数组,返回将每个整数取平方后形成数组的排序后的数组。 | 双指针。一个从左到右,一个从右到左,把平方值较大的数放入输出数组。 | |
| 79 | 4 | Median of Two Sorted Arrays | Link | 给定连个排序好的整数数组,求它们合并后、排序后的数组的中位数。要求时间复杂度为对数级的。 | ||
| 80 | 34 | Find First and Last Position of Element in Sorted Array | Link | 给定一个赠序整数数组,求某个数在数组中出现的最小、最大位置。 | 两次二分查找。分别找到该数的最小位置和最大位置。 | |
| 81 | 53 | Maximum Subarray | Link | 求一个整数数组的子数组,使得该子数组的和最大。 | 两个数值,分别记录包含当前整数的子数组最大值和所有子数组的最大值。遍历完整个数组后,返回最大子数组和。 | |
| 82 | 78 | Subsets | Link | 给定一个有不重复整数组成的数组,求其所有的子集。 | DP。转换关系:已知i个数字组成数组的所有子集,新加一个数组,求这i+1个数字的所有子集。 | |
| 83 | 126 | Word Ladder II | Link | 给定两个字符串beginWord和endWord,和一个字典wordList,在每次只能改变字符串中一个字符的情况下,求如何从beginWord转换到endWord,且中间字符串都要在wordList中。返回最短的转换路径。 | ||
| 84 | 523 | Continuous Subarray Sum | Link | 给定一个整数数组,求它是否存在一个好子数组,满足:该子数组的和是k的整数倍。 | 求数组前缀和,prefix sum,并且用一个字典记录前缀和对应位置。 | |
| 85 | 545 | Boundary of Binary Tree | Link | 给定一个二叉树,求其外围节点组成的数组。 | 深度优先遍历,找到左右边界,再找到所有叶子节点,然后组成外围节点。 | |
| 86 | 708 | Insert into a Sorted Circular Linked List | Link | 给定一个环形链表,链表中的数字是排序好的,即除了最大节点,每个节点的后一个节点的值都大。插入一个新的值,使得该环形链表仍然有序。 | 如果这个值介于链表最大值和最小值之间,则找到一个中间位置即可。如果该值比最大值大,或者比最小值小,则只能插入最大值节点的末尾。 | |
| 87 | 824 | Goat Latin | Link | 根据一些规则转换字符串。 | 直接按规则编写程序。 | |
| 88 | 1768 | Merge Strings Alternately | Link | 把两个字符串合并,要求字符位置穿插。 | 直接按规则编程。 | |
| 89 | 2914 | Minimum Number of Changes to Make Binary String Beautiful | Link | 转换一个字符串,使得它可以被分成一到多份,每份都包含偶数个字符,且只包含‘0’或者‘1’。 | 记住无论怎么分,偶数位置(从0开始)其右边的字符总是分在一起的。所以只要看相邻字符不同的对数,就是所需的最少变换。 | |
| 90 | 3 | Longest Substring Without Repeating Characters | Link | 给定一个字符串,求该字符串的最长子串,该子串不能包含重复字符。 | 滑动窗口,用left,right记录滑动窗口的起点和终点。用一个字典记录每个字符当前的最大位置。为了保证窗口内无重复字符,每次right向右移动一次,就查询字典,检查该字符的上一位置是否在窗口内,若在,就需要更新left。每次right更新,都要记录当前的最长子串。 | |
| 91 | 16 | 3Sum Closest | Link | 给定一个整数数组,找到三个数,使得它们的和离给定整数最近。 | 3 sum问题一般就要想办法转换为2 sum问题。先将数组排序,然后固定最小的那个数,在剩下的书中用双指针法找到最近的组合。 | |
| 92 | 19 | Remove Nth Node From End of List | Link | 给定一个链表,去除从链表尾倒数第n个节点,返回链表。 | 双指针,slow和fast,fast比slow多n步,当fast为空指针时,slow正好是要删除的节点。 | |
| 93 | 40 | Combination Sum II | Link | 给定一个整数数组,求该数组内所有可能的数字组合,使得这些数字的和等于给定target值。 | 递归法。先将数组排序,然后考虑每个元素作为子集中的元素,右边数字进入下一个递归层。 | |
| 94 | 43 | Multiply Strings | Link | 给定两个字符串,代表两个非负整数,返回它们代表整数的乘积,也用字符串表示。 | 从右向左双层遍历每个字符,取它们代表整数的乘积,加到目标位数上。若大于10,则进位。在返回结果的时候,要注意去除高位0。 | |
| 95 | 48 | Rotate Image | Link | 给定一个nxn矩阵,将其顺时针旋转90度。不要额外分配内存。 | 对于矩阵左上1/4部分元素(当n为奇数时,要考虑最中间一行/列),将其于对应的四个角的元素进行旋转操作。 | |
| 96 | 66 | Plus One | Link | 一个数组,每个元素均是0-9的正整数,它们代表了一个大整数的每个位。求该大整数加1后的大整数,也用数组表示返回。 | 有最低位到最高位,考虑进位。 | |
| 97 | 127 | Word Ladder | Link | 给定两个字符串,beginWord和endWord,以及一个字符串list,wordList。每次只可以改动一个字符,且改动后的字符串必须在wordList中。能否通过一系列转换,把beginWord转换为endWord。可以的话,返回最小操作步数,不可以,则返回0。 | 最短路径问题。 | |
| 98 | 139 | Word Break | Link | 给定一个字符串和一个字符串list。是否可以用字符串list中的字符把字符串拆分。 | DP。求每个前缀子字符串是否可以用字符串list中的字符拆分。 | |
| 99 | 143 | Reorder List | Link | 问题描述看链接。 | 快慢指针求中间节点,然后把list一分为二:left_list和right_list。将right_list逆转,然后再和left_list交叉合并。 | |
| 100 | 207 | Course Schedule | Link | 排课问题,有些课必须上了别的课才能上,问能否所有课都上。 | 拓扑排序问题,参考Alien Directory问题的解法。 |